Lesson 2: Shared Memory Architecture
Consider:
A sprawling, high-end commercial restaurant operating at peak dinner rush. In this establishment, there are five hundred specialized chefs. If every single chef operates in absolute isolation—maintaining their own private refrigerator, their own personal pantry, and their own isolated ledger of customer orders—the system collapses under its own weight. Chef A wastes twenty minutes fetching a single onion from the basement, completely unaware that Chef B just brought up a fifty-pound sack of them. The result is catastrophic duplication of effort, extreme resource bloat, and a total inability to serve a unified dining room
To survive the dinner rush, the restaurant requires a massive, hyper-organized, centrally accessible prep arena where ingredients, order tickets, and transaction ledgers are instantly visible and modifiable by any authorized chef, governed by strict rules of engagement.
This is exactly why PostgreSQL cannot simply spawn isolated processes that act independently. The database engine operates on a multi-process architecture (the fork/exec model) rather than a multi-threaded one. Because operating systems strictly isolate the memory spaces of distinct processes for security and stability, PostgreSQL must explicitly request the OS to carve out a massive, communal block of RAM.
This communal arena is the Shared Memory Segment. Without it, PostgreSQL is nothing more than a collection of blind, deaf processes completely incapable of coordinating a concurrent workload. We will map out this shared memory segment, specifically locating `shared_buffers`, WAL buffers, and the commit log (CLOG).
The Architecture of Shared Memory
When the postmaster daemon initializes, before it accepts a single client connection, it allocates a monolithic block of System V or POSIX shared memory. Every subsequent backend process spawned to handle a client connection inherits pointers to this exact same memory space.
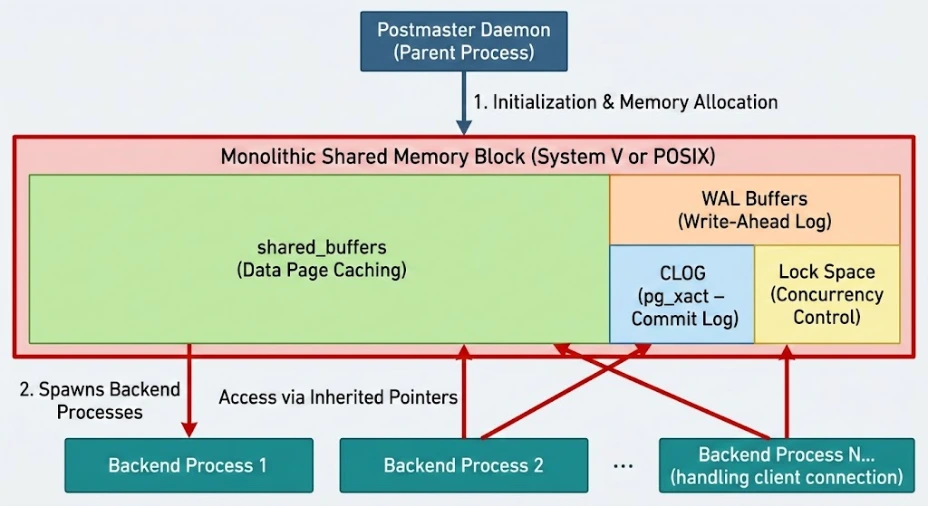
This memory is not a generic pool; it is rigidly structured and subdivided into highly specialized zones. Let us dissect the three most critical structures within this segment.
The `shared_buffers` Pool: The Central Prep Arena
The vast majority of your shared memory segment is consumed by the `shared_buffers` pool. The official documentation in Chapter 19.4: Resource Consumption discusses the configuration limits of this pool. You must violently discard the notion that a database reads from and writes to a disk. Databases read from and write to memory. The disk is merely a persistent, slow-moving backup.
When a backend process needs to read a row, it does not reach for the hard drive. It searches the `shared_buffers`. This pool is an array of exactly 8-kilobyte (8KB) blocks, mirroring the exact 8KB page structure of the data files on disk.
If we examine the C-struct definitions for the shared buffer pool located in `src/include/storage/bufmgr.h`, we see that the pool is divided into two parts:
- Buffer Descriptors: The metadata. Think of these as the labels on the prep station containers. They track which physical disk page is currently held in a specific buffer, whether the buffer is dirty (modified but not yet written to disk), and its usage count.
- Data Blocks: The actual 8KB chunks of raw table or index data.
If Chef A (Backend Process 1) needs to read the `users` table, they load an 8KB page from disk into a slot in `shared_buffers`. If Chef B (Backend Process 2) immediately needs to update a row on that exact same page, they do not go to disk; they modify the page already sitting in the shared buffer pool, marking its descriptor as dirty.
WAL Buffers: The Expeditor's Outbox
While the `shared_buffers` hold the actual data, modifying data strictly in memory introduces a terrifying risk: if the power fails, all **dirty** buffers are wiped from RAM, and your database is destroyed.
To guarantee data durability without forcing the engine to wait for slow, random disk writes on every single transaction, PostgreSQL uses a Write-Ahead Log (WAL). Before a dirty page can be flushed to disk, a record of the *change* must be written to the log.
However, writing directly to the WAL file on disk for every microscopic change is still too slow. Enter the WAL buffers.
Located within the shared memory segment, the WAL buffers act as an ultra-fast, sequentially written staging area. When a backend process modifies a row in `shared_buffers`, it simultaneously writes a tiny, highly compressed description of the change (a WAL record) into the WAL buffers.
Think of this as the expeditor's outbox in our restaurant. The chefs don't run to the mailroom to mail off every individual order receipt. They drop the receipt in the outbox (WAL buffers). A specialized background worker (the WAL Writer) scoops up the entire stack of receipts and writes them to the physical WAL file on disk in one swift, sequential motion. This guarantees durability while maintaining blistering speed.
The Commit Log (CLOG / pg_xact): The Master Ledger
THE CLOG IS NOT A LOG. I must aggressively correct this pervasive naming misconception. Do not let the word "log" deceive you into visualizing a chronological text file of events.
The Commit Log, physically stored in the `pg_xact` directory and cached heavily in the shared memory segment, is a microscopic, hyper-dense array of bits. Its sole purpose is to track the status of every single Transaction ID (XID) that has ever existed in the cluster.
In our restaurant, this is the master ledger at the host stand. It doesn't contain the details of what was ordered; it simply contains a light that is either red, yellow, or green indicating if Table 42 has paid their bill.
Every transaction in PostgreSQL is assigned an XID. The CLOG allocates exactly two bits of memory to represent the state of that transaction. The states are:
00 | In Progress |
01 | Committed |
10 | Aborted (Rolled back) |
11 | Sub-transaction committed |
Because it only uses two bits per transaction, calculating the exact byte offset in the CLOG for a specific XID is a matter of simple, highly efficient bitwise arithmetic:
$$\text{Byte\_Offset} = \lfloor \frac{\text{XID}}{4} \rfloor$$
When a backend process is scanning a page in `shared_buffers` and sees a row modified by XID 1,048,576, it must know: Did this transaction successfully finish, or did it fail? The backend queries the shared memory CLOG, jumps directly to the mathematically computed byte offset, reads the two bits, and instantly knows if the data is valid or if it should be ignored.
Summary
The PostgreSQL multi-process architecture demands a centralized nervous system to function. This is the Shared Memory Segment. It is the communal arena where isolated processes collaborate. We mapped out three critical zones within it:
- `shared_buffers`: The massive array of 8KB blocks where physical table and index data is cached, read, and modified.
- WAL Buffers: The sequential staging area where records of modifications are temporarily held before being flushed to disk, ensuring durability.
- Commit Log (CLOG): The hyper-dense bit-array that acts as the absolute source of truth for the committed or aborted status of every transaction.
Without this shared architecture, concurrent relational data management is physically impossible.
Synthesis
Return to the commercial restaurant bottleneck presented at the beginning of the lesson (Consider: ...). Write a comment that briefly explains (in a few sentences) how the implementation of the `shared_buffers` pool physically solves the problem of Chef A fetching an onion from the basement while Chef B fetches a fifty-pound sack of them, and how it prevents memory bloat across the hundreds of active chefs.
There are no comments for now.
to be the first to leave a comment.